Kubeadm介绍 Kubeadm 是一个提供了 kubeadm init 和 kubeadm join 的可作为快速创建 Kubernetes 集群的工具。
Kubernetes 练习环境
K8s组件介绍 官方文档:https://kubernetes.io/zh-cn/docs/concepts/overview/components
控制平面组件(Control Plane Components) 控制平面组件会为集群做出全局决策,比如资源的调度。 以及检测和响应集群事件,例如当不满足部署的 replicas 字段时,要启动新的 Pod)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # kube-apiserver API 服务器是 Kubernetes 控制平面的组件, 该组件负责公开了 Kubernetes API,负责处理接受请求的工作。 API 服务器是 Kubernetes 控制平面的前端。 # etcd 一致且高可用的键值存储,用作 Kubernetes 所有集群数据的后台数据库。 # kube-scheduler kube-scheduler 是控制平面的组件, 负责监视新创建的、未指定运行节点(node)的 Pods, 并选择节点来让 Pod 在上面运行。 # kube-controller-manager kube-controller-manager 是控制平面的组件, 负责运行控制器进程。 # cloud-controller-manager 一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager) 允许将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
Node 组件 节点组件会在每个节点上运行,负责维护运行的 Pod 并提供 Kubernetes 运行环境。
1 2 3 4 5 6 7 8 # kubelet kubelet 会在集群中每个节点(node)上运行。 它保证容器(containers)都运行在 Pod 中。 # kube-proxy kube-proxy 是集群中每个节点(node)上所运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。 # 容器运行时(Container Runtime) 这个基础组件使 Kubernetes 能够有效运行容器。 它负责管理 Kubernetes 环境中容器的执行和生命周期。
插件(Addons) 插件使用 Kubernetes 资源(DaemonSet、 Deployment 等)实现集群功能。 因为这些插件提供集群级别的功能,插件中命名空间域的资源属于 kube-system 命名空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # DNS 尽管其他插件都并非严格意义上的必需组件,但几乎所有 Kubernetes 集群都应该有集群 DNS, 因为很多示例都需要 DNS 服务。 # Web 界面(Web UI/Dashboard) Dashboard 是 Kubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身, 并进行故障排除。 # 容器资源监控(Container Resource Monitoring) 容器资源监控 将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中, 并提供浏览这些数据的界面。 # 集群层面日志(Cluster-level Logging) 集群层面日志机制负责将容器的日志数据保存到一个集中的日志存储中, 这种集中日志存储提供搜索和浏览接口。 # 网络插件(Network Plugins) 网络插件 是实现容器网络接口(CNI)规范的软件组件。它们负责为 Pod 分配 IP 地址,并使这些 Pod 能在集群内部相互通信。
版本选择
生产环境中,建议使用小版本大于5的Kubernetes版本,比如1.26.5以后的才可用于生产环境。
版本偏差策略
架构选择 使用 kubeadm 部署高可用集群时,etcd集群可以放到 master 节点上可节约资源且方便管理,也可以使用外部的etcd集群,可用性更高(这种方式安装的集群,证书有效期只有一年,需要定期轮换)。
基本环境配置
Hostname
IP
OS
Kernel
VM specifications
Desc
Master-121-123
192.168.111.121-123
CentOS 7.9
5.4
2c4g 100GB
VIP: 192.168.111.100
Worker-124-126
192.168.111.124-126
CentOS 7.9
5.4
4c8g 100GB
环境检查官方文档
兼容的 Linux 主机。
每台机器CPU 2 核心、RAM 2 GB及以上。
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)。
节点之中不可以有重复的主机名、MAC 地址或 product_uuid 。
开启机器上的某些端口 。
交换分区的配置(建议禁用)。
Linux操作系统需要包含glibc环境。
K8s Service、Pod网段划分
Name
DESC
Pod网段
172.16.0.0/12
Service网段
172.20.0.0/16
自动化工具准备
runsh 自动化脚本工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 # !/bin/bash # Batch processing tools host_port=22 host_user="root" user_option=$1 host_ips=$2 case ${user_option} in cmd) exec_command=$(cat <<EOF $ 3 EOF ) for host_ip in $(cat ${host_ips});do echo -e "--->>> ${host_ip} <<<---" #result=$(ssh -p $host_port -T ${host_user}@${host_ip} -C ${exec_command}) ssh -p $host_port -T ${host_user}@${host_ip} -C "${exec_command}" echo -e "\n" #if [ $? -ne 0 ];then # echo -e "Faild.\n" #fi done ;; scp) source_file_dir=$3 target_file_dir=$4 for host_ip in $(cat ${host_ips});do echo -e "--->>> ${host_ip} <<<---" scp -P ${host_port} ${source_file_dir} "${host_user}@${host_ip}:${target_file_dir}" if [ $? -ne 0 ];then echo -e "Faild.\n" fi done ;; help) echo 'Usage: runsh [ OPTIONS ] OBJECT COMMAND where OPTIONS := { cmd | scp } OBJECT := /path/to/ip_file_directory COMMAND := { "bash command" | /path/to/source_file_directory[Using "" to include multiple files] /path/to/target_file_directory }' ;; *) echo -e "Object \"${user_option}\" is unknown, try 'runsh help'" # echo -e "-runsh: ${user_option} Unknown command, try 'runsh help'" exit 1 ;; esac
1 2 # master121 chmod +x /usr/local/bin/runsh
配置免密(Master-121)
创建ip文件
node.ips
1 2 3 4 5 192.168.111.121 192.168.111.122 192.168.111.123 192.168.111.124 192.168.111.125
master.ips
1 2 3 192.168.111.121 192.168.111.122 192.168.111.123
worker.ips
1 2 192.168.111.124 192.168.111.125
hosts
1 2 3 4 5 192.168.111.121_master-121 192.168.111.122_master-122 192.168.111.123_master-123 192.168.111.124_worker-124 192.168.111.125_worker-125
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # master-121 ssh-keygen -t rsa -f /root/.ssh/id_rsa -N '' mkdir -p /opt/deploy-k8s/ips/ cd /opt/deploy-k8s # 根据提示输入密码 for host_ip in $(cat ips/node.ips);do ssh-copy-id -i ~/.ssh/id_rsa.pub root@${host_ip} done # 配置主机名,详情见 hosts for host in $(cat ips/hosts);do ssh root@${host%_*} -C "hostnamectl set-hostname ${host#*_}" done # 为 Master/Worker节点添加主机名解析(deploy-node) runsh cmd ips/node.ips "echo '192.168.111.121 master-121 192.168.111.122 master-122 192.168.111.123 master-123 192.168.111.124 worker-124 192.168.111.125 worker-125' >> /etc/hosts"
常用软件安装
所有节点安装
master-121作为下发命令根服务器 = deploy-node
1 2 3 4 5 6 7 8 9 10 11 12 13 # deploy-node # 配置yum源 curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo cd /opt/deploy-k8s runsh scp ips/node.ips /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/ runsh cmd ips/node.ips "yum install -y vim wget net-tools yum-utils bash-completion tree git psmisc device-mapper-persistent-data lvm2" # 配置k8s自动补全 runsh cmd ips/node.ips "echo \"source <(kubectl completion bash)\" >> ~/.bashrc" runsh cmd ips/node.ips "source /usr/share/bash-completion/bash_completion" runsh cmd ips/node.ips "source < (kubectl completion bash)"
1 2 3 # deploy-node mkdir -p /opt/deploy-k8s/repos runsh scp ips/node.ips repos/kubernetes.repo /etc/yum.repos.d/
kubernetes.repo
1 2 3 4 5 6 [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/ enabled=1 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/repodata/repomd.xml.key
检查 Mac 地址、product_uuid
确保Mac地址唯一(Master/Worker节点)
确保product_uuid唯一(Master/Worker节点)
1 2 3 # deploy-node runsh cmd ips/node.ips "ip addr show ens33 | awk '/ether/{print \$2}'" runsh cmd ips/node.ips "cat /sys/class/dmi/id/product_uuid"
关闭 Swap 分区
确保禁用Swap分区(Master/Worker节点)
1 2 3 4 5 6 7 # deploy-node # 关闭swap分区 runsh cmd ips/node.ips "swapoff -a" runsh cmd ips/node.ips "sed -i '/^[^#].*swap/s/^/#/' /etc/fstab" # 检查 runsh cmd ips/node.ips "free -h | grep Swap"
关闭 firewalld、selinux、dnsmasq
CentOS 7 需要关闭NetworkManager,CentOS 8 不需要(Master/Worker节点)
1 2 3 4 5 6 7 8 9 # deploy-node runsh cmd ips/node.ips "systemctl disable firewalld --now; systemctl disable dnsmasqd --now; systemctl disable NetworkManager --now" runsh cmd ips/node.ips "setenforce 0; sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config" # 检查 runsh cmd ips/node.ips "systemctl is-active firewalld; systemctl is-enabled firewalld" runsh cmd ips/node.ips "systemctl is-active dnsmasq; systemctl is-enabled dnsmasq" runsh cmd ips/node.ips "systemctl is-active NetworkManager; systemctl is-enabled NetworkManager" runsh cmd ips/node.ips "getenforce; grep '^SELINUX=' /etc/selinux/config"
配置时间同步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # deploy-node runsh cmd ips/node.ips "ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime" runsh cmd ips/node.ips "echo 'Asia/Shanghai' > /etc/timezone" # 安装时间同步服务 runsh cmd ips/node.ips "yum install -y chrony && systemctl enable chronyd --now" # 查看时间同步 runsh cmd ips/node.ips "systemctl is-active chronyd; systemctl is-enabled chronyd; chronyc sources stats" # 查看时区 runsh cmd ips/node.ips "date '+%F %T %z'" # 手动同步时间 runsh cmd ips/node.ips "chronyc makestep" runsh cmd ips/node.ips "systemctl restart chronyd"
配置limits.conf
1 2 3 4 5 6 7 8 # deploy-node runsh cmd ips/node.ips "ulimit -SHn 65535" runsh cmd ips/node.ips "echo '* soft nofile 65536 * hard nofile 131072 * soft nproc 65535 * hard nproc 655350 * soft memlock unlimited * hard memlock unlimited' >> /etc/security/limits.conf"
升级内核版本
CentOS 7 需要升级到4.18+,升级内核版本到5.4(所有节点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # deploy-node wget -P /opt/deploy-k8s/repos https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-lt-5.4.275-1.el7.elrepo.x86_64.rpm wget -P /opt/deploy-k8s/repos https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-lt-devel-5.4.275-1.el7.elrepo.x86_64.rpm # 安装内核 runsh scp ips/node.ips "repos/kernel-lt*.rpm" /usr/local/src/ runsh cmd ips/node.ips "cd /usr/local/src && yum localinstall -y kernel-lt*" # 更改内核启动顺序 # 根据系统当前的内核配置和安装情况,自动生成 GRUB 的菜单配置文件 runsh cmd ips/node.ips "grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg" runsh cmd ips/node.ips "grubby --args=\"user_namespace.enable=1\" --update-kernel=\"\$(grubby --default-kernel)\"" # 检查默认启动内核 runsh cmd ips/node.ips "grubby --default-kernel" # 重启服务器,重启后检查 runsh cmd ips/node.ips "reboot" runsh cmd ips/node.ips "uname -r"
K8s必要内核参数配置(Master/Worker节点)
conf/k8s-sysctl.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 fs.may_detach_mounts = 1 vm.overcommit_memory = 1 net.ipv4.conf.all.route_localnet = 1 vm.panic_on_oom=0 fs.inotify.max_user_watches=89100 fs.file-max=52706963 fs.nr_open=52706963 net.netfilter.nf_conntrack_max=2310720 net.ipv4.tcp_keepalive_time = 600 net.ipv4.tcp_keepalive_probes = 3 net.ipv4.tcp_keepalive_intvl =15 net.ipv4.tcp_max_tw_buckets = 36000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_max_orphans = 327680 net.ipv4.tcp_orphan_retries = 3 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_max_syn_backlog = 16384 net.ipv4.ip_conntrack_max = 65536 net.ipv4.tcp_max_syn_backlog = 16384 net.ipv4.tcp_timestamps = 0 net.core.somaxconn = 16384
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # deploy-node mkdir -p /opt/deploy-k8s/conf runsh scp ips/node.ips conf/k8s-sysctl.conf /etc/sysctl.d/k8s-sysctl.conf runsh cmd ips/node.ips "sysctl --system" # 其他内核参数(待确认) net.core.netdev_max_backlog = 65535 net.ipv4.tcp_timestamps = 1 net.ipv4.tcp_syn_retries = 2 net.ipv4.tcp_synack_retries = 2 net.ipv4.tcp_max_syn_backlog = 65535 net.core.somaxconn = 65535 net.ipv4.tcp_max_tw_buckets = 8192 net.ipv4.ip_local_port_range = 10240 65000 vm.swappiness = 0
安装ipvsadm
1 2 3 # deploy-node runsh cmd ips/node.ips "yum install -y ipset ipvsadm sysstat conntrack libseccomp" runsh cmd ips/node.ips "which ipset ipvsadm"
开启ipvs和br_netfilter内核模块
如果内核版本超过4.19,安装nf_conntrack,4.18 以下安装nf_conntrack_ipv4 (Master/Worker节点)
ipvs/ipvs-modules.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp ip_vs_sh nf_conntrack ip_tables ip_set xt_set ipt_set ipt_rpfilter ipt_REJECT ipip br_netfilter
1 2 3 4 5 6 7 8 9 10 # deploy-node mkdir -p /opt/deploy-k8s/ipvs # 加载模块 runsh scp ips/node.ips ipvs/ipvs-modules.conf /etc/modules-load.d/ipvs-modules.conf runsh cmd ips/node.ips "systemctl enable systemd-modules-load.service --now" # runsh cmd ips/node.ips "awk '{print \"modprobe --\",\$1}' /etc/modules-load.d/ipvs-module.conf | bash" # 查看模块是否成功加载 runsh cmd ips/node.ips "lsmod | awk '/^ip_vs|^nf_conntrack|^br_netfilter/{print \$1}'"
基本组件安装 安装 container runtime 所有节点,安装containerd 1 2 3 4 5 6 7 # deploy-node mkdir -p /opt/deploy-k8s/containerd runsh cmd ips/node.ips "yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo" runsh cmd ips/node.ips "yum install -y containerd.io" runsh cmd ips/node.ips "systemctl enable containerd --now" runsh cmd ips/node.ips "containerd config default > /etc/containerd/config.toml"
修改 containerd 配置文件
sandbox_image 修改 pause 地址需要和 kubelet 中的一致(在第63行修改),再配置镜像仓库的加速器地址(在第155行后,新增156行到160行的内容),根据实际情况修改
1 2 3 4 5 6 7 8 9 10 63c63 < sandbox_image = "registry.k8s.io/pause:3.6" --- > sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9" 155a156,160 > [plugins."io.containerd.grpc.v1.cri" .registry.mirrors."docker.io" ] > endpoint = ["https://ustc-edu-cn.mirror.aliyuncs.com" , "https://hub-mirror.c.163.com" ] > > [plugins."io.containerd.grpc.v1.cri" .registry.mirrors."k8s.gcr.io" ] > endpoint = ["registry.aliyuncs.com/google_containers" ]
安装 kubeadm、kubelet、kubectl yum安装kubeadm
1 2 3 4 5 6 7 # deploy-node # 查看可用版本,并选择执行版本安装 yum list kubeadm.x86_64 --showduplicates | sort -r runsh cmd ips/node.ips "yum install -y kubeadm-1.28.8* kubelet-1.28.8* kubectl-1.28.8*" # yum 安装 kubelet 时会自动安装 CNI插件 runsh cmd ips/node.ips "ls /opt/cni"
配置pause 默认配置的pause镜像使用gcr.io仓库,国内可能无法访问,需要换源,执行 kubeadm config images pull --config /root/kubeadm-init.yaml 时可以看到pause版本
1 2 3 4 5 # deploy-node cat pause/kubelet KUBELET_EXTRA_ARGS="--cgroup-driver=systemd --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause-amd64:3.9" runsh scp ips/node.ips pause/kubelet /etc/sysconfig/
启动kubelet 1 runsh cmd ips/node.ips "systemctl daemon-reload; systemctl enable kubelet --now"
kubeadm故障排查 1 2 3 4 5 6 7 8 9 10 11 12 1. 添加删除节点证书问题 1.1 所需要被添加的节点,通过kubeadm reset 清空k8s环境 1.2 清空cni插件配置目录 1.3 清空iptables 规则 1.4 master节点,通过查看添加证书命令,执行添加节点操作 kubeadm token create --print-join-command 2. 如何重新生成证书 kubeadm init phase upload-certs --upload-certs 3. 查看证书过期时间 kubeadm alpha certs check-expiration
安装高可用组件
不是高可用集群,不用安装haproxy和keepalived
公有云要使用公有云自带的负载均衡,因为公有云大部分不支持keepalived。
阿里云的SLB:kubectl控制端不能放在master节点(SLB代理的服务器不能反向访问SLB)
腾讯云的ELB
安装HAproxy和Keepalived
所有master节点,安装HAproxy和Keepalived
1 2 3 # deploy-node mkdir -p /opt/deploy-k8s/lb/{haproxy,keepalived/master-12{1,2,3}} runsh cmd ips/master.ips "yum install -y haproxy keepalived"
配置HAproxy
1 2 # deploy-node runsh scp ips/master.ips /opt/deploy-k8s/lb/haproxy/haproxy.cfg /etc/haproxy/
配置Keepalived
master-122,keepalived.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ! Configuration File for keepalived global_defs { router_id LVS_DEVEL } vrrp_script chk_apiserver { script "/etc/keepalived/check_apiserver.sh" interval 5 weight -5 fall 2 rise 1 } vrrp_instance VI_1 { state BACKUP interface ens33 mcast_src_ip 192.168.111.122 virtual_router_id 51 priority 100 nopreempt advert_int 2 authentication { auth_type PASS auth_pass K8SHA_AUTH123 } virtual_ipaddress { 192.168.111.100 } track_script { chk_apiserver } }
master-123,keepalived.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ! Configuration File for keepalived global_defs { router_id LVS_DEVEL } vrrp_script chk_apiserver { script "/etc/keepalived/check_apiserver.sh" interval 5 weight -5 fall 2 rise 1 } vrrp_instance VI_1 { state BACKUP interface ens33 mcast_src_ip 192.168.111.123 virtual_router_id 51 priority 100 nopreempt advert_int 2 authentication { auth_type PASS auth_pass K8SHA_AUTH123 } virtual_ipaddress { 192.168.111.100 } track_script { chk_apiserver } }
master-121~3,check_apiserver.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # !/bin/bash err=0 for k in $(seq 1 3) do check_code=$(pgrep haproxy) if [[ $check_code == "" ]]; then err=$(expr $err + 1) sleep 1 continue else err=0 break fi done if [[ $err != "0" ]]; then echo "systemctl stop keepalived" /usr/bin/systemctl stop keepalived exit 1 else exit 0 fi
1 2 3 4 5 6 # deploy-k8s chmod +x /opt/deploy-k8s/lb/keepalived/check_apiserver.sh scp /opt/deploy-k8s/lb/keepalived/master-121/keepalived.conf root@192.168.111.121:/etc/keepalived/ scp /opt/deploy-k8s/lb/keepalived/master-122/keepalived.conf root@192.168.111.122:/etc/keepalived/ scp /opt/deploy-k8s/lb/keepalived/master-123/keepalived.conf root@192.168.111.123:/etc/keepalived/ runsh scp ips/master.ips /opt/deploy-k8s/lb/keepalived/check_apiserver.sh /etc/keepalived/
启动并测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # deploy-node # 所有master节点,启动haproxy和keepalived runsh cmd ips/master.ips "systemctl daemon-reload; systemctl enable haproxy --now; systemctl enable keepalived --now" # VIP测试,重要:如果安装了keepalived和haproxy,需要测试keepalived是否是正常的 ping 192.168.111.100 telnet 192.168.111.100 8443 # VIP不通问题定位 需要排查keepalived的问题,比如防火墙和selinux,haproxy和keepalived的状态,监听端口等 所有节点查看防火墙状态必须为disable和inactive:systemctl status firewalld 所有节点查看selinux状态,必须为disable:getenforce master节点查看haproxy和keepalived状态:systemctl status keepalived haproxy master节点查看监听端口:netstat -lntp
集群初始化 1 2 3 4 5 6 # master-121 mkdir -p /opt/deploy-k8s/kubeadm cd /opt/deploy-k8s/kubeadm # 根据当前版本生成 kubeadm 配置文件,并根据实际情况修改参数 kubeadm config print init-defaults > kubeadm-config.yaml
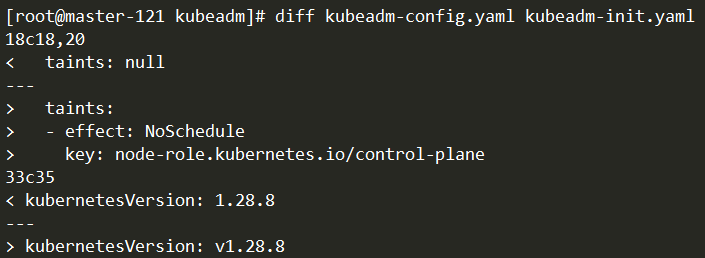
kubeadm-config.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.111.121 bindPort: 6443 nodeRegistration: criSocket: unix:///var/run/containerd/containerd.sock imagePullPolicy: IfNotPresent name: master-121 taints: - effect: NoSchedule key: node-role.kubernetes.io/control-plane --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controlPlaneEndpoint: 192.168.111.100:8443 controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: v1.28.8 networking: dnsDomain: cluster.local podSubnet: 172.16.0.0/12 serviceSubnet: 172.20.0.0/16 scheduler: {}
更新 kubeadm 配置文件
advertiseAddress: 192.168.111.121 为 master-121 的ipname: master-121 为 master-121 的 hostnamecontrolPlaneEndpoint 修改为 VIP,如果不是高可用集群,改为 master-121 的地址,8443 改为 apiserver 的端口,默认是6443imageRepository 修改为国内镜像地址kubernetesVersion: v1.28.8 为实际 kubeadm 的版本podSubnet: 172.16.0.0/12 为 Pod 网段serviceSubnet: 172.20.0.0/16 为 Service 网段bootstrapTokens 请随机生成,必须符合正则表达式[a-z0-9]{6}\.[a-z0-9]{16}
随机生成token脚本
1 2 3 4 5 6 7 8 9 10 11 12 # cat token_generator.sh# !/bin/bash # token_id token_id=$(tr -dc 'a-z0-9' < /dev/urandom | fold -w 6 | head -n 1) # token_secret token_secret=$(tr -dc 'a-z0-9' < /dev/urandom | fold -w 16 | head -n 1) # full token full_token="${token_id}.${token_secret}" echo "$full_token"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 cp kube-config.yaml kube-config.yaml.default # 根据实际情况修改 diff kube-config.yaml kube-config.yaml.default 12c12 < advertiseAddress: 192.168.111.121 --- > advertiseAddress: 1.2.3.4 17c17 < name: master-121 --- > name: node 25d24 < controlPlaneEndpoint: 192.168.111.100:8443 31c30 < imageRepository: registry.aliyuncs.com/google_containers --- > imageRepository: registry.k8s.io 33c32 < kubernetesVersion: 1.28.8 --- > kubernetesVersion: 1.28.0 36,37c35 < podSubnet: 172.16.0.0/12 < serviceSubnet: 172.20.0.0/16 --- > serviceSubnet: 10.96.0.0/12
1 2 # 检查 migrate 后的,kubeadm-init.yaml 文件 kubeadm config migrate --old-config kubeadm-config.yaml --new-config kubeadm-init.yaml
1 2 3 4 5 6 7 8 # 将 kubeadm-init.yaml 文件复制到其他 master 节点 runsh scp ips/master.ips /opt/deploy-k8s/kubeadm/kubeadm-init.yaml ~/ # 所有 Master节点 提前下载镜像 runsh cmd ips/master.ips "kubeadm config images pull --config /root/kubeadm-init.yaml" # 所有节点设置开机自启动kubelet,如果启动失败无需管理,初始化成功以后即可启动 runsh cmd ips/master.ips "systemctl enable kubelet --now"
可能出现的问题
执行 kubeadm config images pull --config /root/kubeadm-init.yaml 命令报如下错误
1 2 3 failed to pull image "registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.8": output: time="2024-05-18T21:20:54+08:00" level=fatal msg="validate service connection: validate CRI v1 imck\": rpc error: code = Unimplemented desc = unknown service runtime.v1.ImageService" , error: exit status 1 To see the stack trace of this error execute with --v=5 or higher
原因是 cni 插件被禁用
1 2 sed -i 's/cri//' /etc/containerd/config.toml systemctl daemon-reload; systemctl restart containerd
节点初始化
1 2 3 # master-121 # 初始化以后会在 /etc/kubernetes 目录下生成对应的证书和配置文件,之后其他Master节点加入 Master-121 即可 kubeadm init --config /root/kubeadm-init.yaml --upload-certs
初始化成功以后,会产生Token值,用于其他节点加入时使用
初始化过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 # kubeadm init --config /root/kubeadm-init.yaml --upload-certs [init] Using Kubernetes version: v1.28.8 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master-121] and IPs [172.20.0.1 192.168.111.121 192.168.111.100] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost master-121] and IPs [192.168.111.121 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost master-121] and IPs [192.168.111.121 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" W0519 00:13:03.334688 7802 endpoint.go:57] [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "admin.conf" kubeconfig file W0519 00:13:03.406217 7802 endpoint.go:57] [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "kubelet.conf" kubeconfig file W0519 00:13:03.637342 7802 endpoint.go:57] [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "controller-manager.conf" kubeconfig file W0519 00:13:03.684709 7802 endpoint.go:57] [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "scheduler.conf" kubeconfig file [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 3.976649 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [upload-certs] Using certificate key: 9c1155ba51ac5ccc3d00ef24eb37628d14552966e6db643e846d6d2af06a85b9 [mark-control-plane] Marking the node master-121 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers] [mark-control-plane] Marking the node master-121 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule] [bootstrap-token] Using token: 2spn5y.mcrkq3v0v4zi7fw9 [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS W0519 00:13:09.345195 7802 endpoint.go:57] [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 192.168.111.100:8443 --token 2spn5y.mcrkq3v0v4zi7fw9 \ --discovery-token-ca-cert-hash sha256:d8e434af47eb587c2584f8e828e8617cc6ebfdd0f9e1ad8e535b77ff06c5e71e \ --control-plane --certificate-key 9c1155ba51ac5ccc3d00ef24eb37628d14552966e6db643e846d6d2af06a85b9 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.111.100:8443 --token 2spn5y.mcrkq3v0v4zi7fw9 \ --discovery-token-ca-cert-hash sha256:d8e434af47eb587c2584f8e828e8617cc6ebfdd0f9e1ad8e535b77ff06c5e71e
初始化失败操作 1 2 # 重置后再次初始化 kubeadm reset -f; ipvsadm --clear; rm -rf ~/.kube
访问集群配置
master-121配置,用于访问Kubernetes集群
1 2 3 4 cat >> /root/.bashrc <<EOF export KUBECONFIG=/etc/kubernetes/admin.conf EOF source /root/.bashrc
集群扩容/其他节点加入集群
根据集群初始化提示可知,作为一种保护措施,上传的证书将在两小时内删除kubeadm init phase upload-certs --upload-certs 重新加载证书
1 2 3 # master-121 # kubeadm token create --print-join-command kubeadm init phase upload-certs --upload-certs
添加 master节点
You can now join any number of the control-plane node running the following command on each as root:
1 2 3 kubeadm join 192.168.111.100:8443 --token 2spn5y.mcrkq3v0v4zi7fw9 \ --discovery-token-ca-cert-hash sha256:d8e434af47eb587c2584f8e828e8617cc6ebfdd0f9e1ad8e535b77ff06c5e71e \ --control-plane --certificate-key 9c1155ba51ac5ccc3d00ef24eb37628d14552966e6db643e846d6d2af06a85b9
添加 worker 节点
Then you can join any number of worker nodes by running the following on each as root:
1 2 kubeadm join 192.168.111.100:8443 --token 2spn5y.mcrkq3v0v4zi7fw9 \ --discovery-token-ca-cert-hash sha256:d8e434af47eb587c2584f8e828e8617cc6ebfdd0f9e1ad8e535b77ff06c5e71e
查看节点状态
采用初始化安装方式,所有的系统组件均以容器的方式运行并且在 kube-system 命名空间内,此时可以查看Pod状态
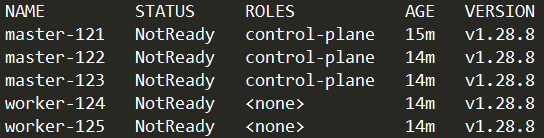
1 2 3 # master-121 kubectl get nodes kubectl get pod -n kube-system
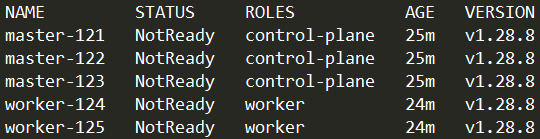
1 2 3 4 # 配置 worker 节点的角色 kubectl label node worker-124 node-role.kubernetes.io/worker=true kubectl label node worker-125 node-role.kubernetes.io/worker=true kubectl get nodes
节点状态为 NotReady,根据初始化信息可知,需要安装网络插件
安装网络插件Calico 必须部署一个基于 Pod 网络插件的 容器网络接口 (CNI) ,以便你的 Pod 可以相互通信。 在安装网络之前,集群 DNS (CoreDNS) 将不会启动。
1 2 3 # master-121 wget https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/tigera-operator.yaml wget https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/custom-resources.yaml
配置 Calico 1 2 3 4 5 6 7 8 9 # master-121 # kubeadm init ... # podSubnet: 172.16.0.0/12 # criSocket: unix:///var/run/containerd/containerd.sock sed -i "s/192.168/172.16/" custom-resources.yaml kubectl create -f tigera-operator.yaml kubectl create -f custom-resources.yaml watch -n1 kubectl get pods -n calico-system
安装Ingress Controller Ingress 可为 Service 提供外部可访问的 URL、对其流量作负载均衡、 终止 SSL/TLS,以及基于名称的虚拟托管等能力。 Ingress Controller 负责完成 Ingress 的工作。
数据请求流程 实现反向代理的 Gateway 的请求数据流如下:
客户端开始准备 URL 为 http://www.example.com 的 HTTP 请求
客户端的 DNS 解析器查询目标名称并了解与 Gateway 关联的一个或多个 IP 地址的映射。
客户端向 Gateway IP 地址发送请求;反向代理接收 HTTP 请求并使用 Host: 标头来匹配基于 Gateway 和附加的 HTTPRoute 所获得的配置。
可选的,反向代理可以根据 HTTPRoute 的匹配规则进行请求头和(或)路径匹配。
可选地,反向代理可以修改请求;例如,根据 HTTPRoute 的过滤规则添加或删除标头。
最后,反向代理将请求转发到一个或多个后端。
安装Ingress-NGINX
1 2 3 4 # deploy-k8s mkdir -p /opt/deploy-k8s/ingress cd /opt/deploy-k8s/ingress wget -O ingress-nginx-controller.yaml https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.10.0/deploy/static/provider/cloud/deploy.yaml
更新配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 sed -i 's@image: .*controller.*@image: registry.aliyuncs.com/google_containers/nginx-ingress-controller:v1.10.0@' ingress-nginx-controller.yaml sed -i 's@image: .*kube-webhook-certgen.*@image: registry.aliyuncs.com/google_containers/kube-webhook-certgen:v1.4.0@' ingress-nginx-controller.yaml # diff ingress-nginx-controller.yaml ingress-nginx-controller.yaml.default 446c446 < image: registry.aliyuncs.com/google_containers/nginx-ingress-controller:v1.10.0 --- > image: registry.k8s.io/ingress-nginx/controller:v1.10.0@sha256:42b3f0e5d0846876b1791cd3afeb5f1cbbe4259d6f35651dcc1b5c980925379c 547c547 < image: registry.aliyuncs.com/google_containers/kube-webhook-certgen:v1.4.0 --- > image: registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.4.0@sha256:44d1d0e9f19c63f58b380c5fddaca7cf22c7cee564adeff365225a5df5ef3334 600c600 < image: registry.aliyuncs.com/google_containers/kube-webhook-certgen:v1.4.0 --- > image: registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.4.0@sha256:44d1d0e9f19c63f58b380c5fddaca7cf22c7cee564adeff365225a5df5ef3334
部署ingress nginx controller
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 kubectl apply -f ingress-nginx-controller.yaml # 清理 kubectl delete -f ingress-nginx-controller.yaml # 查看pod kubectl get pods -n ingress-nginx NAME READY STATUS RESTARTS AGE ingress-nginx-admission-create-wmqf8 0/1 Completed 0 1m ingress-nginx-admission-patch-9zdvw 0/1 Completed 0 1m ingress-nginx-controller-d854966d-pt44t 1/1 Running 0 1m # 当 nginx-admission-create 和 ingress-nginx-admission-patch 这两个 Pod 被创建时,它将开始运行容器,执行必要的初始化和验证操作,然后尝试处理 Kubernetes API server 发送的请求。如果请求已经被处理完毕,容器将正常终止,并将Pod的状态设置为Completed。因此,Pod处于Completed状态并不表示有任何问题或错误,而是表示容器已经完成了它需要完成的任务并终止了运行。 # 需要注意的是,如果在Pod终止之前出现错误或异常,Pod的状态将会被设置为Failed,这可能需要进行进一步的故障排除和修复 # 查看Service # kubectl get svc -n ingress-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress-nginx-controller NodePort 172.20.248.186 <none> 80:32080/TCP,443:32443/TCP 2m ingress-nginx-controller-admission ClusterIP 172.20.224.227 <none> 443/TCP 2m
安装Mertics
Metrics Server 从 Kubelet 收集资源指标,并通过Metrics API在 Kubernetes apiserver 中公开,请勿将其用于将指标转发到监控解决方案,或作为监控解决方案指标的来源。
官方文档:https://github.com/kubernetes-sigs/metrics-server
适用于大多数集群的单一部署(请参阅要求 )
快速自动缩放,每 15 秒收集一次指标。
资源效率,集群中每个节点使用 1 mili 核心 CPU 和 2 MB 内存。
可扩展支持多达 5,000 个节点集群。
下载Mertics配置文件 1 2 3 4 # deploy-node mkdir -p /opt/deploy-k8s/mertics cd /opt/deploy-k8s/mertics wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
更新配置文件并启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 1. 替换镜像仓库地址 # 2. 增加 --kubelet-insecure-tls 启动参数,跳过证书验证 grep -w -E "image|kubelet-insecure-tls" components.yaml image: registry.k8s.io/metrics-server/metrics-server:v0.7.1 # 修改参考如下 140,141c140 < - --kubelet-insecure-tls < image: registry.aliyuncs.com/google_containers/metrics-server:v0.7.1 --- > image: registry.k8s.io/metrics-server/metrics-server:v0.7.1 # 部署mertics kubectl apply -f components.yaml
查看节点资源 安装Kubernetes Dashboard
Dashboard 是基于网页的 Kubernetes 用户界面。 你可以使用 Dashboard 将容器应用部署到 Kubernetes 集群中,也可以对容器应用排错,还能管理集群资源。使用单容器 DBless Kong 安装作为连接所有容器并公开 UI 的网关。然后,使用 kong 网关前面的任何入口控制器或代理访问 Dashboard 。
安装Helm Github主页:https://github.com/helm/helm
1 2 3 4 5 6 7 8 9 10 11 # deploy-k8s mkdir -p /opt/deploy-k8s/helm cd /opt/deploy-k8s/helm wget https://get.helm.sh/helm-v3.15.0-linux-amd64.tar.gz tar tf helm-v3.15.0-linux-amd64.tar.gz linux-amd64/ linux-amd64/README.md linux-amd64/LICENSE linux-amd64/helm tar xf helm-v3.15.0-linux-amd64.tar.gz --strip-components=1 -C /usr/local/bin/ linux-amd64/helm
配置 helm 命令行补全 1 2 echo "source <(helm completion bash)" >> ~/.bashrc source /root/.bashrc
安装dashboard 拉取dashboard 1 2 3 4 5 6 7 8 9 10 # deploy-node # 添加 helm kubernetes-dashboard 仓库 helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/ # 查看 helm 仓库 helm repo list # 查询 dashboard chart helm search repo kubernetes-dashboard mkdir -p /opt/deploy-k8s/dashboard; cd /opt/deploy-k8s/dashboard helm pull kubernetes-dashboard/kubernetes-dashboard
配置dashboard yaml
1 2 3 tar -xf kubernetes-dashboard-7.4.0.tgz cd kubernetes-dashboard cp values.yaml dashboard.yaml
部署dashboard 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 # deploy-node cd /opt/deploy-k8s/dashboard/kubernetes-dashboard # 修改镜像仓库地址 sed -i 's@docker.io@m.daocloud.io/docker.io@g' dashboard.yaml diff dashboard.yaml values.yaml 129c129 < repository: m.daocloud.io/docker.io/kubernetesui/dashboard-auth --- > repository: docker.io/kubernetesui/dashboard-auth 166c166 < repository: m.daocloud.io/docker.io/kubernetesui/dashboard-api --- > repository: docker.io/kubernetesui/dashboard-api 221c221 < repository: m.daocloud.io/docker.io/kubernetesui/dashboard-web --- > repository: docker.io/kubernetesui/dashboard-web 279c279 < repository: m.daocloud.io/docker.io/kubernetesui/dashboard-metrics-scraper --- > repository: docker.io/kubernetesui/dashboard-metrics-scraper # 单独设置Kong仓库地址,yaml文件暂未找到仓库设置位置 helm install kube-dashboard kubernetes-dashboard/kubernetes-dashboard \ -f dashboard.yaml \ --namespace kube-dashboard \ --create-namespace \ --set kong.image.repository=m.daocloud.io/docker.io/library/kong \ --set kong.image.tag=3.6 # 查看 kubectl get pods -n kube-dashboard kubectl get svc -n kube-dashboard # helm删除dashboard helm delete kube-dashboard -n kube-dashboard
配置ingress 修改Ingress访问方式 当使用 K8S 中的 Ingress 资源对象来暴露应用时,用户访问应用的入口是 Ingress Controller 的地址,常见的暴露方式有以下几种:
LoadBalancer
如果 Kubernetes 集群运行在支持负载均衡器的云服务上,如 AWS、Azure、Google Cloud 等;将 Ingress Controller 暴露到云服务提供商的负载均衡器上,从而可以通过负载均衡器的 IP 地址来访问 Ingress Controller。
NodePort
这种类型在每个节点的网络上开放一个端口,并在所有节点上暴露同一个端口。可以通过 <节点IP>:<节点端口> 访问服务。NodePort 的缺点是它不提供负载均衡,且端口范围有限(默认是 30000-32767)。
ClusterIP
默认的类型,它会为服务分配一个集群内的 IP 地址,这个地址只能在集群内部访问。对于 Ingress 来说,通常不会直接使用 ClusterIP,因为 Ingress 的目的是为了从集群外部访问服务。
配置NodePort方式
修改 ingress-nginx-controller.yaml 配置文件,找到 kind: Service,参考如下配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 cd /opt/deploy-k8s/ingress vim ingress-nginx-controller.yaml ... apiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/component: controller app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx app.kubernetes.io/version: 1.10.0 name: ingress-nginx-controller namespace: ingress-nginx spec: externalTrafficPolicy: Local ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - appProtocol: http name: http port: 80 protocol: TCP targetPort: http nodePort: 32080 # 新增nodePort,默认端口范围:30000-32767 - appProtocol: https name: https port: 443 protocol: TCP targetPort: https nodePort: 32443 # 新增nodePort,默认端口范围:30000-32767 selector: app.kubernetes.io/component: controller app.kubernetes.io/instance: ingress-nginx app.kubernetes.io/name: ingress-nginx type: NodePort # 将type从 LoadBalancer 修改为 NodePort ...
1 2 3 4 5 6 kubectl delete -f ingress-nginx-controller.yaml kubectl create -f ingress-nginx-controller.yaml # 查看pod 和 service 状态 kubectl get pod -n ingress-nginx -o wide kubectl get svc -n ingress-nginx
配置dashboard https 自签名证书1 下载生成证书工具 1 2 3 4 5 # master-121 wget "https://pkg.cfssl.org/R1.2/cfssl_linux-amd64" -O /usr/local/bin/cfssl wget "https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64" -O /usr/local/bin/cfssljson chmod +x /usr/local/bin/cfssl /usr/local/bin/cfssljson which cfssl cfssljson
创建证书配置文件
cert.json
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 { "hosts": [ "k8s.dashboard.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Beijing", "L": "Beijing", "O": "system:masters", "OU": "Kubernetes-manual", "CN": "k8s.dashboard.local" } ] }
生成证书和密钥 1 2 3 4 5 6 7 # master-121 cd /opt/deploy-k8s/dashboard/certs cfssl gencert -initca cert.json | cfssljson -bare k8s.dashboard.local # 将生成三个文件:k8s.dashboard.local.csr、k8s.dashboard.local-key.pem、k8s.dashboard.local.pem # k8s.dashboard.local-key.pem 是证书私钥文件 # k8s.dashboard.local.pem 是证书文件
自签证书2(可选)
1 2 3 4 5 6 # master-121 cd /opt/deploy-k8s/ingress/rules openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout kube-dashboard.key -out kube-dashboard.crt -subj "/CN=dashboard.kube.com/O=k8s.dashboard.local" # 此处的 dashboard-tls-secret 需要和 ingress-dashboard 中的secretName中一致 kubectl create secret tls dashboard-tls-secret --key kube-dashboard.key --cert kube-dashboard.crt -n kube-dashboard
公网证书
从证书颁发机构(CA)购买 SSL 证书,或者使用 Let’s Encrypt 这样的免费服务来获取证书。
1 2 # master-121 kubectl create secret tls your-domain-tls --key=path/to/private.key --cert=path/to/cert.pem
创建k8s secret对象
将生成的证书和密钥文件打包成一个k8s secret对象
dashboard-tls-secret 是 secret 对象的名称,需要和 ingress-dashboard.yaml 的 secretName 一致--key 参数指定私钥文件的路径--cert 参数指定证书文件的路径
1 2 kubectl create secret tls dashboard-tls-secret --key k8s.dashboard.local-key.pem --cert k8s.dashboard.local.pem kubectl get secret
创建dashboard ingress
ingress-dashboard.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: kubernetes-dashboard-ingress namespace: kube-dashboard annotations: kubernetes.io/ingress.class: nginx nginx.ingress.kubernetes.io/backend-protocol: "HTTPS" spec: ingressClassName: nginx tls: - hosts: - k8s.dashboard.local secretName: dashboard-tls-secret rules: - host: k8s.dashboard.local http: paths: - path: / pathType: Prefix backend: service: name: kube-dashboard-kong-proxy port: number: 443
如果需要,可以添加其他 annotations 来配置 TLS 和证书等
1 2 3 4 5 6 # master-121 cd /opt/deploy-k8s/ingress/rules kubectl apply -f ingress-dashboard.yaml kubectl get ingress -n kube-dashboard NAME CLASS HOSTS ADDRESS PORTS AGE kubernetes-dashboard-ingress nginx k8s.dashboard.local 172.20.248.186 80, 443 3m
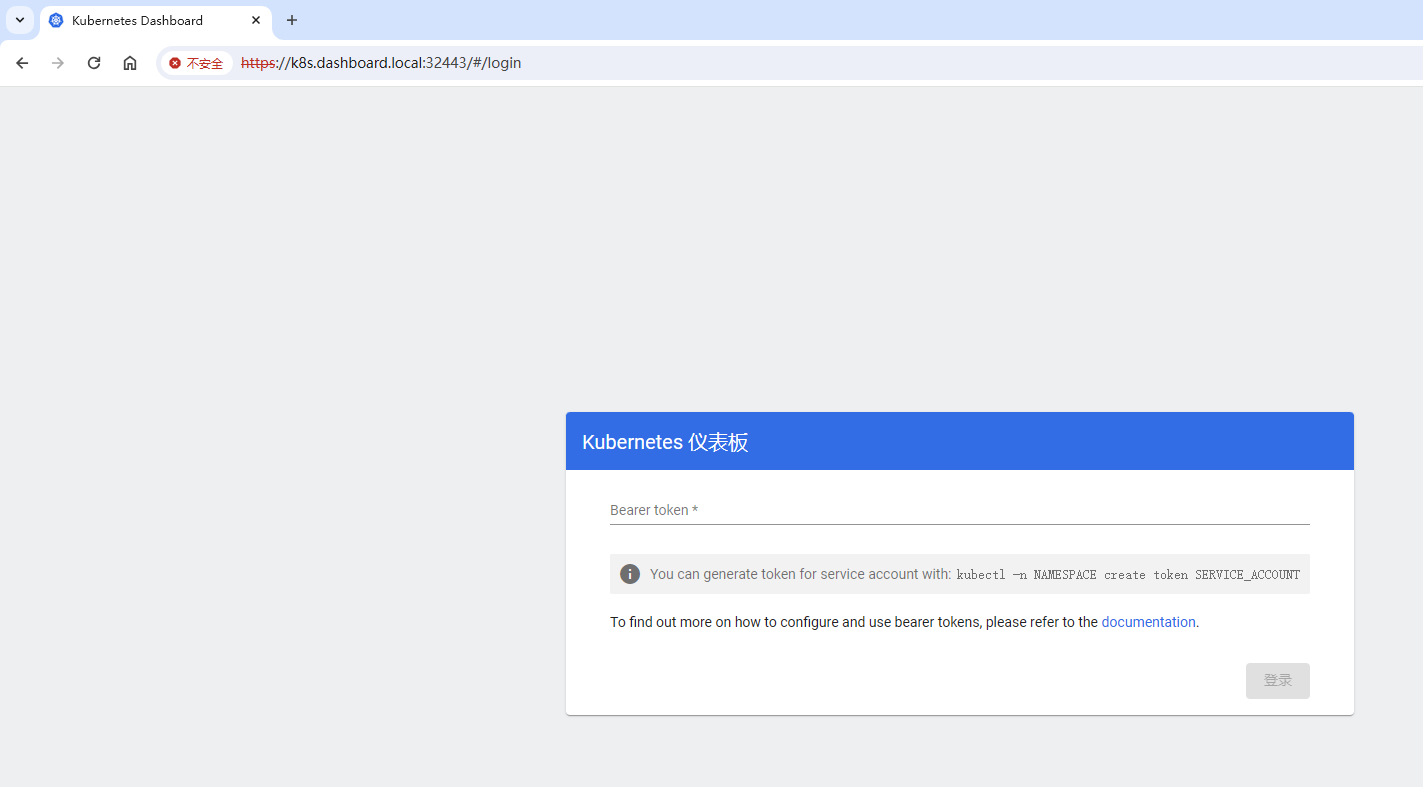
访问dashboard
通过 kubectl get pods -n ingress-nginx -o wide 看到 ingress-nginx-controller 部署在 125
本地通过 hosts 文件将域名 k8s.dashboard.local 解析到 192.168.111.125
即可通过浏览器访问 https://k8s.dashboard.local:32443
创建dashboard用户和生成token 创建管理员用户
dashboard-user.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system
1 2 3 4 5 # master-121 cd /opt/deploy-k8s/dashboard/create-users kubectl apply -f dashboard-user.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created
创建用户Token
1 2 3 # master-121 kubectl -n kube-system create token admin-user eyJhbGciOiJSUzI1NiIsImtpZCI6ImRFbWlFZ2NPeTY2VjlEcWg5dzlrQjJJN1V3QUdiR2pvbm1FcVM4Y1J6UTgifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwILnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiMDI3N2E3NjctOTAwNy00Mjk0LWI5udDprdWJlLXN5c3RlbTphZG1pbi11c2VyIn0.2XJ0MAKSI_iiRrntYWj0ANcHqPTiowM2QupTm8sO2lKjKf3iUeI0lFnDuT2nueDLNpO1IKTV0je9rOyaoR9ZaTYC3KXGPOPvgpX4YRtiGQj8gZFzFV95VZxMUtlIi_ZY1cl1-sYTRjXMq5XwPLjNbMnCTXliUwtpMKjoNhJZlP7HnhZ9xsf5DEUhopc6hKuNDrewFixOMwS6RbkbXH-tY-HVrVTam0wuPIJu6TnFtKMbzpzwMvEMptMTeKNnPUoHXuA
创建长期Token
dashboard-admin-user-token.yaml
1 2 3 4 5 6 7 8 apiVersion: v1 kind: Secret metadata: name: admin-user namespace: kube-system annotations: kubernetes.io/service-account.name: "admin-user" type: kubernetes.io/service-account-token
1 2 3 4 5 6 7 8 # master-121 cd /opt/deploy-k8s/dashboard/create-users kubectl apply -f dashboard-user-token.yaml secret/admin-user created # 查看用户token kubectl -n kube-system get secret admin-user -o jsonpath={".data.token"} | base64 -d eyJhbGciOiJSUzI1NiIsImtpZCI6ImRFbWlFZ2NPeTY2VjlEcWg5dzlrQjJJN1V3QUdiR2pvbm1FcVM4Y1J6UTgifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjbOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIwMjc3YTc2Ny05MDA3LTQyOTQtYjk0Yi1kYWZlOGI2OGJlNmMiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW45sbXFhYggqjlo1KNOviGRUPP_sPoqKhzt7rA-Qm9cPyqusHi7Mp23YDYM6qojtdV2Ya-M2hIQiavUl99WTIW-cHHDt2AtO7vrucdThSYW3edVxCGa1LPsXBPz_tRXBoAAwxTnmUsNEhr63rhxy_gEFFUWAN9j4QWt6EFXDxL2cT
注意事项
kubeadm 安装的集群,证书有效期默认是一年
master 节点的 kube-apiserver、kube-scheduler、kube-controller-manager、etcd 都是以容器运行的,可以通过kubectl -n kube-system get pod 查看
启动和二进制不同的是,kubelet的配置文件在/etc/sysconfig/Kubelet 其他组件的配置文件在/etc/kubernetes目录下,比如kube-apiserver.yaml,该yaml文件更改后,kubelet会自动刷新配置,也就是会重启pod,不能再次创建该文件
官方 kubernetes dashboard 里面的编辑,添加等操作都是 yaml 格式形式编辑,国内开发的 https://kuboard.cn/ 比较好用(初始用户名/密码,admin/Kuboard123)